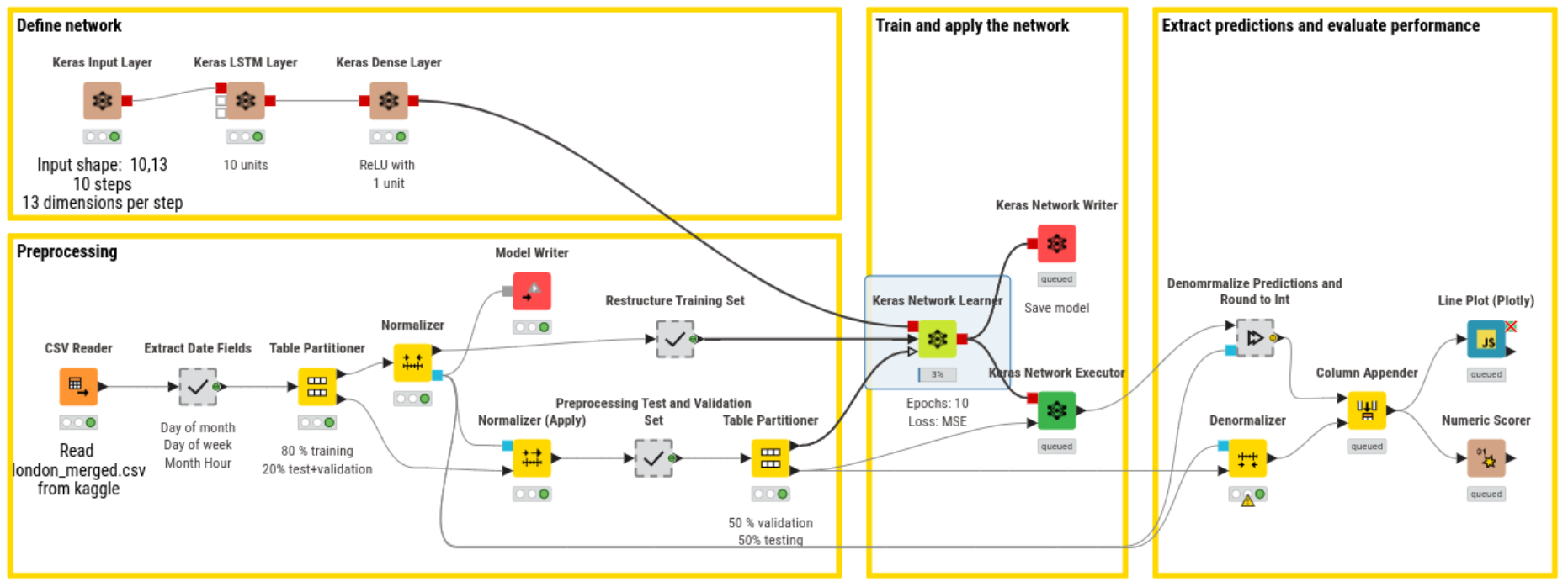
Opción 2 Informe Ejecutivo: Clasificación de Dígitos con Redes Convolucionales¶
Esta actividad tiene como objetivo aplicar un modelo de red neuronal convolucional (CNN) para resolver un problema de clasificación de imágenes de dígitos escritos a mano, usando el conjunto de datos MNIST. Además de entrenar el modelo, se analizará el proceso de aprendizaje a través de mapas de activación y se evaluará su desempeño con una matriz de confusión y un reporte de clasificación.
📝 Instrucciones¶
1. Definición de arquitectura y entrenamiento del modelo¶
Se construyó una red neuronal convolucional que recibe imágenes de tamaño 28×28×1 (escala de grises). La arquitectura incluye:
- Dos capas convolucionales con activación
ReLU - Dos capas de reducción espacial con
MaxPooling - Una capa densa intermedia
- Una capa de salida con 10 neuronas y
softmax
📄 Resumen del modelo:
input → Conv2D(8 filtros) → MaxPool → Conv2D(16 filtros) → MaxPool → Flatten → Dense(64) → Dense(10)
🧩 Actividad:
- ¿Por qué la imagen de entrada es de forma
(28, 28, 1)? - ¿Qué función cumple la capa
Flatten? - ¿Por qué la capa de salida tiene 10 neuronas?
- Explica cómo cambia el tamaño de los datos en cada etapa del modelo.
2. Visualización de mapas de activación¶
Se seleccionó una imagen del dígito 7 del conjunto de prueba y se visualizaron los mapas de activación producidos por cada filtro en las dos capas convolucionales.

🧩 Actividad:
- ¿Qué tipo de patrones observas en los filtros de la primera capa (Conv1)?
- ¿Qué detectan los filtros de la segunda capa (Conv2)? ¿Cómo se diferencian de la primera?
- ¿Por qué es importante este tipo de visualización para interpretar una CNN?
3. Evaluación del modelo con matriz de confusión¶
Después del entrenamiento, se evaluó el modelo usando todo el conjunto de prueba. La siguiente figura muestra la matriz de confusión con los resultados obtenidos:
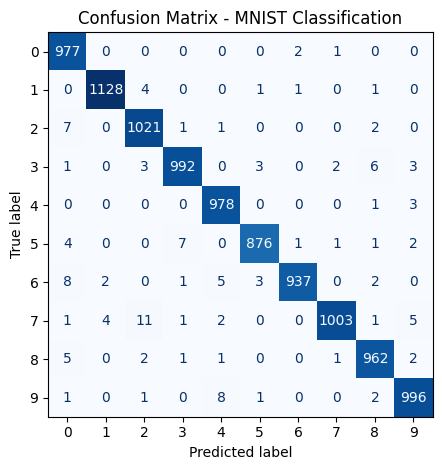
🧩 Actividad:
- ¿Qué dígitos fueron clasificados correctamente con mayor frecuencia?
- ¿En qué clases se cometieron más errores de confusión?
- ¿Qué implicaciones tiene esto para una posible aplicación práctica?
Después del entrenamiento, se evaluó el modelo CNN con el conjunto de prueba. Se presentan a continuación la matriz de confusión y el reporte de clasificación por clase, que permiten analizar el desempeño del modelo para cada dígito.
📄 Reporte de clasificación (conjunto de prueba):
precision recall f1-score support
0 0.97 1.00 0.98 980
1 0.99 0.99 0.99 1135
2 0.98 0.99 0.98 1032
3 0.99 0.98 0.99 1010
4 0.98 1.00 0.99 982
5 0.99 0.98 0.99 892
6 1.00 0.98 0.99 958
7 1.00 0.98 0.99 1028
8 0.98 0.99 0.99 974
9 0.99 0.99 0.99 1009
accuracy 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000📊 Actividad:
- ¿Qué clases muestran mayor precisión y cuáles presentan errores?
- ¿El modelo tiende a confundir alguna clase específica?
- ¿Cómo interpretarías el valor de accuracy y la diferencia entre macro y weighted average?
- ¿Qué importancia tiene el equilibrio entre precisión y recall en este tipo de tareas?
- ¿Qué métricas destacarías para evaluar el modelo?
- ¿Existe alguna clase con peor desempeño? ¿A qué se podría deber?
- ¿Cómo se relaciona el desempeño con la complejidad visual del dígito?
5. Reflexión final¶
🧩 Actividad:
- ¿Consideras que este modelo convolucional es adecuado para el problema?
- ¿Qué modificaciones propondrías para mejorar el rendimiento?
- ¿Cómo se compara esta arquitectura con una red neuronal multicapa (MLP) tradicional?
⏱️ Tiempo estimado de desarrollo: 2 horas ✍️ Entrega: Informe ejecutivo con respuestas justificadas y discusión de las visualizaciones presentadas.