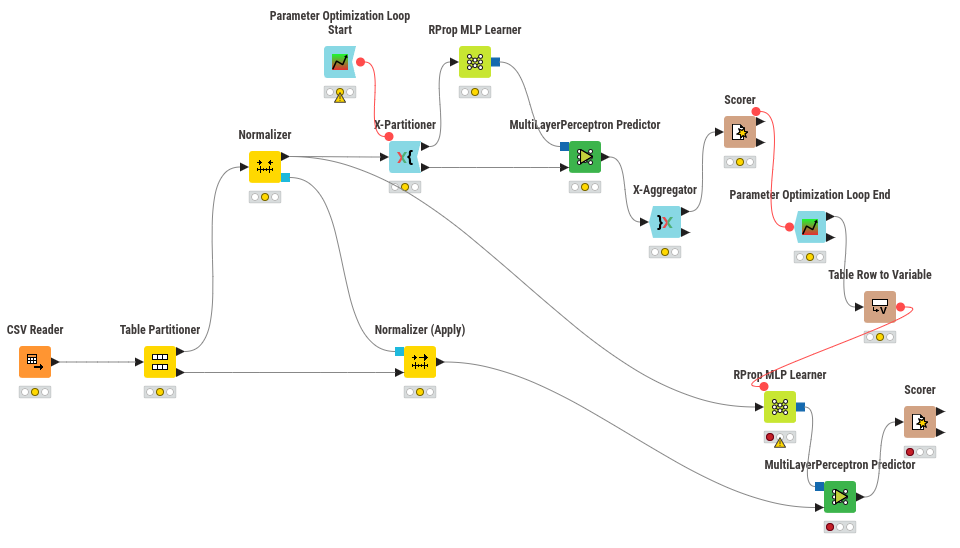
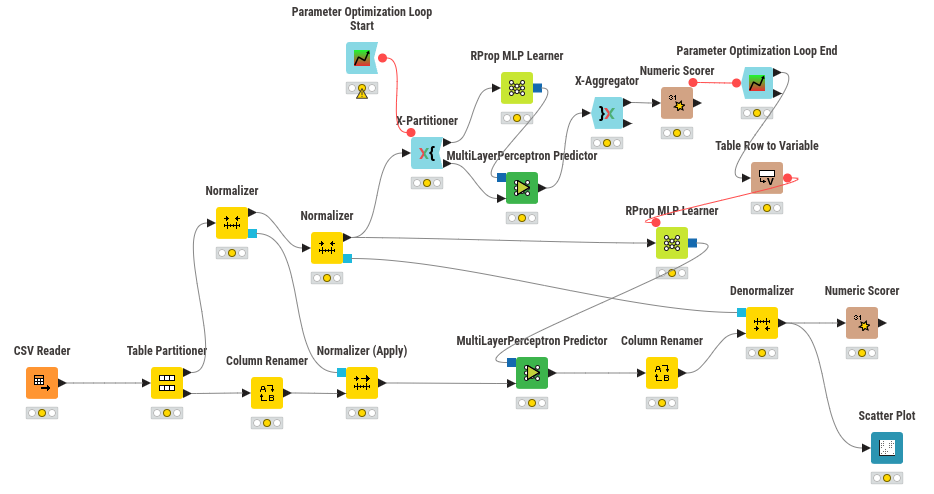
🧠 Opción 2: Clasificación con Redes Neuronales (Informe Ejecutivo)¶
Esta actividad tiene como objetivo aplicar un modelo de red neuronal multicapa para resolver un problema de clasificación binaria (detección de tumores benignos o malignos). El análisis se realiza sobre el conjunto de datos Breast Cancer Wisconsin.
📝 Instrucciones¶
1. Exploración inicial del conjunto de datos¶
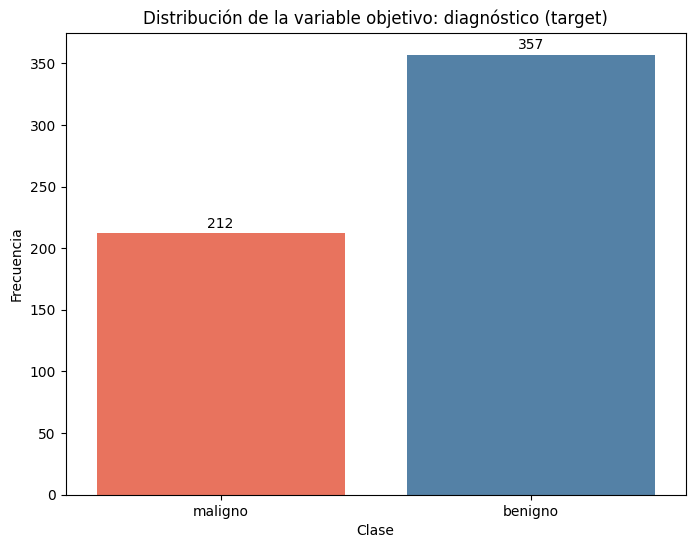
Revisa la distribución de la variable objetivo. Analiza el gráfico adjunto que muestra la cantidad de casos malignos y benignos.
🧩 Actividad:
- ¿Está balanceado el conjunto de datos?
- ¿Por qué puede ser importante considerar el balance de clases en un modelo de clasificación?
2. Proceso de entrenamiento y validación¶
Explica con tus palabras en qué consiste el proceso de dividir el conjunto de datos en entrenamiento y prueba. Describe también qué significa realizar una validación cruzada de 10 folds.
🧩 Actividad:
- ¿Por qué es útil separar los datos en entrenamiento y prueba?
- ¿Qué ventajas ofrece la validación cruzada?
3. Optimización del modelo: selección de hiperparámetros¶
Se entrenó un modelo de red neuronal (MLPClassifier) aplicando una búsqueda en malla (Grid Search) con validación cruzada estratificada de 10 folds. Esta técnica permite probar distintas combinaciones de parámetros del modelo para encontrar la que maximiza el rendimiento.
Los hiperparámetros explorados fueron:
| Hiperparámetro | Valores considerados | Descripción breve |
|---|---|---|
hidden_layer_sizes |
(50,), (100,), (200,) | Cantidad de neuronas en la capa oculta |
activation |
'relu', 'tanh' |
Función de activación utilizada en las neuronas |
alpha |
0.0001, 0.001, 0.01 | Coeficiente de regularización L2 (evita sobreajuste) |
🧠 Mejor configuración encontrada:
{'mlpclassifier__activation': 'relu', 'mlpclassifier__alpha': 0.0001, 'mlpclassifier__hidden_layer_sizes': (200,)}
🧩 Actividad:
- Explica qué rol juega cada uno de estos hiperparámetros en el entrenamiento de una red neuronal.
- ¿Qué podría indicar que la mejor configuración tenga 200 neuronas y use
relu? - ¿Qué importancia tiene el valor bajo de
alphaen este caso?
4. Evaluación con validación cruzada (10 folds)¶
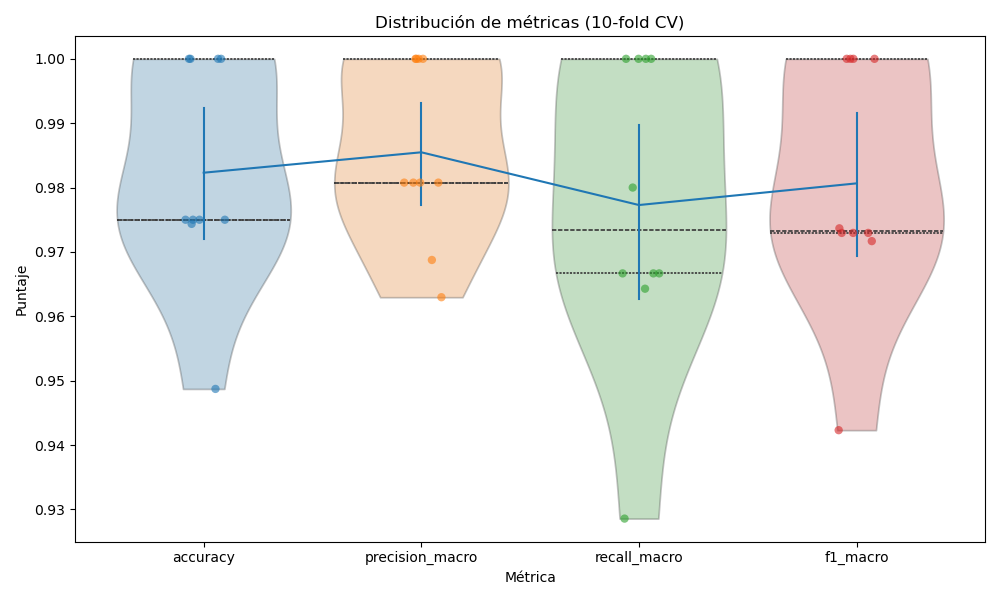
Se calcularon métricas de desempeño en validación cruzada utilizando los siguientes indicadores:
| Métrica | Media | Desviación estándar |
|---|---|---|
| Accuracy | 0.9823 | 0.0172 |
| Precision_macro | 0.9855 | 0.0138 |
| Recall_macro | 0.9773 | 0.0235 |
| F1_macro | 0.9807 | 0.0191 |
🧩 Actividad:
- Interpreta los valores promedio y su dispersión.
- ¿Qué te indica el gráfico de violines sobre la estabilidad de cada métrica?
5. Evaluación en el conjunto de prueba¶
Se evaluó el desempeño del modelo entrenado sobre el 30% del conjunto de datos reservado para prueba. Aquí están las métricas:
📄 Reporte de clasificación (conjunto de prueba):
| Clase | Precision | Recall | F1-score | Soporte |
|---|---|---|---|---|
| Benigno | 0.96 | 1.00 | 0.98 | 107 |
| Maligno | 1.00 | 0.92 | 0.96 | 64 |
| Accuracy: 0.97 |
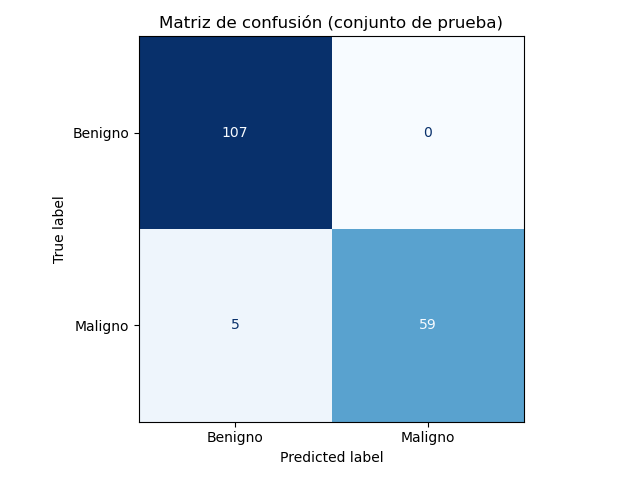
🧩 Actividad:
- ¿Cómo interpretar la matriz de confusión? ¿Qué tipos de error se observan?
- ¿Cuál es el desempeño del modelo para cada clase?
- ¿Cuál métrica destacarías como más relevante en un problema de salud como este?
6. Reflexión final¶
🧩 Actividad:
- ¿Consideras que el modelo es adecuado para este tipo de problema?
- ¿Qué mejorarías o explorarías en una siguiente iteración? (por ejemplo, otros modelos, nuevas variables, balanceo de clases, más datos, etc.)
⏱️ Tiempo estimado de desarrollo: 2 horas ✍️ Entrega: Informe ejecutivo con respuestas a cada sección y discusión de los gráficos presentados.