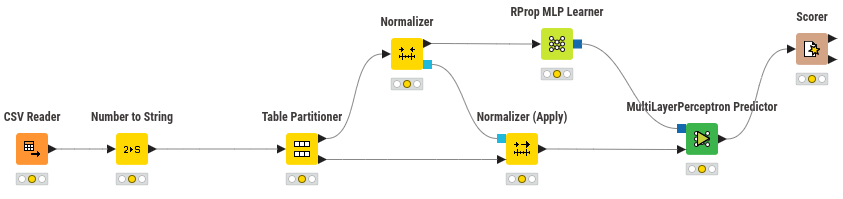
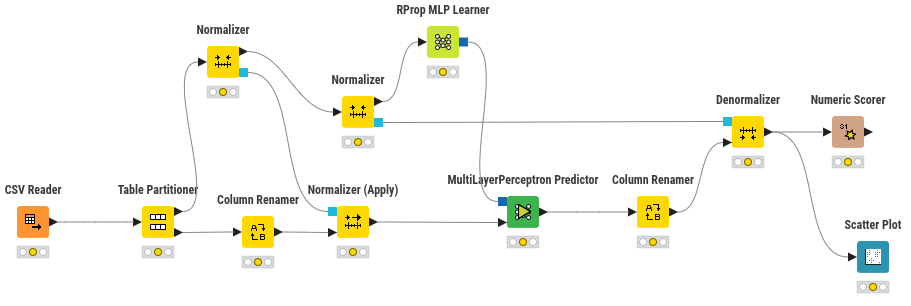
📝 Opción 2- Informe Ejecutivo: Clasificación de Diagnóstico de Cáncer de Mama con MLPClassifier¶
Elabore un informe, de máximo 3 páginas, describiendo el proceso seguido para entrenar un modelo de red neuronal multicapa (MLP) utilizando datos clínicos de diagnóstico de cáncer de mama. El objetivo fue clasificar los tumores como benignos o malignos, a partir de medidas obtenidas de imágenes médicas. A continuación se detalla el proceso seguido, dividido en seis etapas clave. Analice cada sección utilizando las figuras y resultados proporcionados.
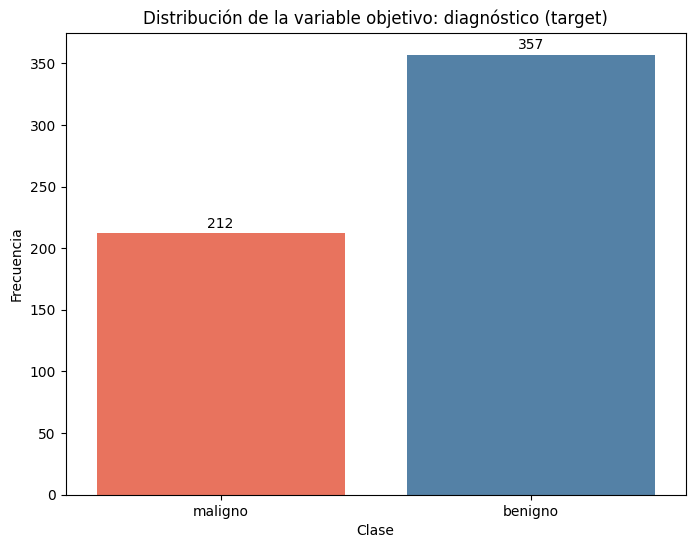
1. Frecuencia de la Variable Objetivo¶
Describa la distribución de las clases maligno y benigno en el conjunto de datos. Analice si existe desbalance y qué implicaciones podría tener.
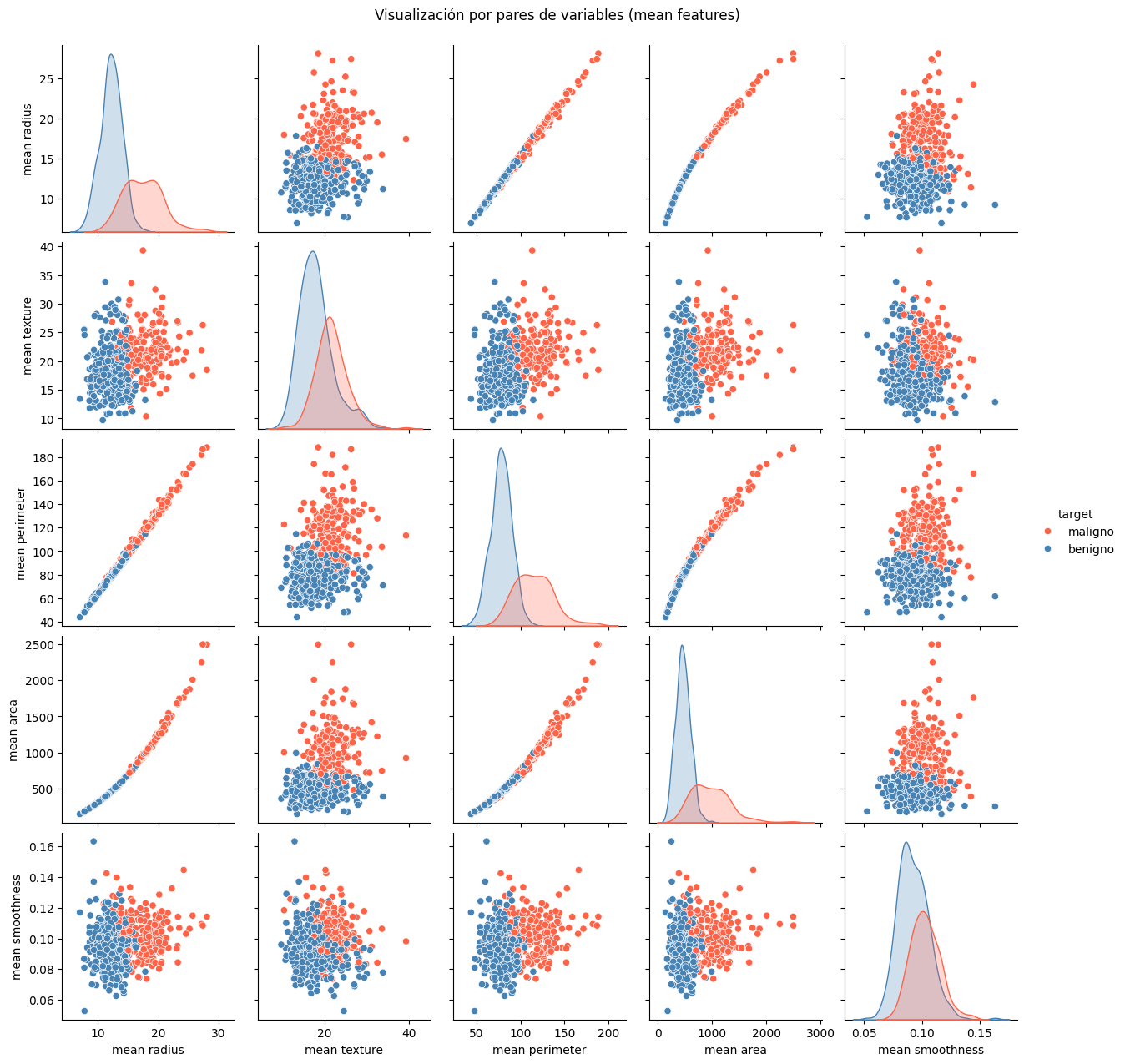
2. Visualización de Variables Numéricas¶
Comente las relaciones visuales entre las variables numéricas seleccionadas. ¿Qué patrones o separaciones observas entre las clases?
3. División de Datos: Entrenamiento y Prueba¶
Explique cómo se dividió el conjunto de datos (porcentaje, estratificación) y justifique si es adecuado para este tipo de problema.
4. Escalamiento de Variables¶
Justifique el uso de StandardScaler. ¿Qué importancia tiene el escalamiento previo al entrenamiento de una red neuronal?
5. Modelado con MLPClassifier¶
Describa brevemente la arquitectura utilizada (número de capas, neuronas, iteraciones) y la función del modelo MLPClassifier.
6. Evaluación del Modelo¶
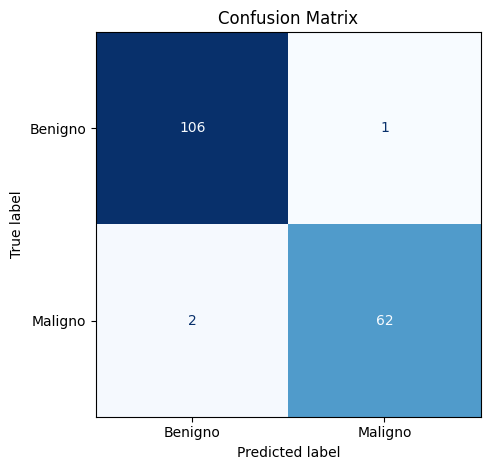
a) Matriz de Confusión
Analice el desempeño del modelo con base en los valores observados en la matriz de confusión.
b) Reporte de Clasificación
Comente los valores de precisión, recall y F1-score. ¿El modelo clasifica bien ambas clases?
Reporte de clasificación:
precision recall f1-score support
benigno 0.98 0.99 0.99 107
maligno 0.98 0.97 0.98 64
accuracy 0.98 171
macro avg 0.98 0.98 0.98 171
weighted avg 0.98 0.98 0.98 171✅ Conclusión¶
Redacte una conclusión ejecutiva sobre el desempeño general del modelo, su aplicabilidad al problema de diagnóstico médico, y posibles mejoras futuras.